Azure AutoML vs. Custom Model Development
This project compared two ways to solve a regression problem: automated machine learning in Azure AutoML and a custom Jupyter Notebook workflow. The use case was shipping-cost prediction for art and collectible objects.
Data-science question
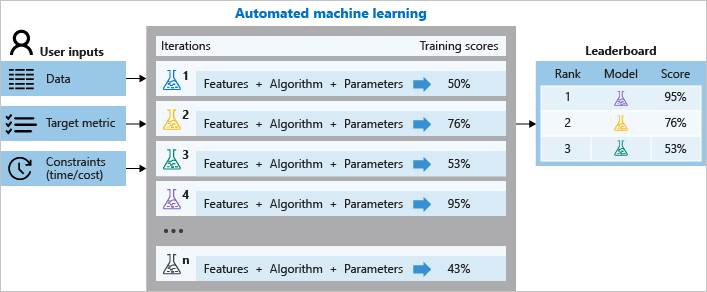
AutoML can accelerate experimentation, but it does not remove the need for careful problem framing. The comparison asked when a fast automated baseline is enough, and when custom feature engineering, validation design, and interpretability are worth the extra work.
Modeling context
The dataset included package dimensions, weight, transport mode, fragile-item indicators, customer and delivery locations, scheduled dates, delivery dates, and shipping cost. The target was continuous, making the project a practical regression study.
What it demonstrates
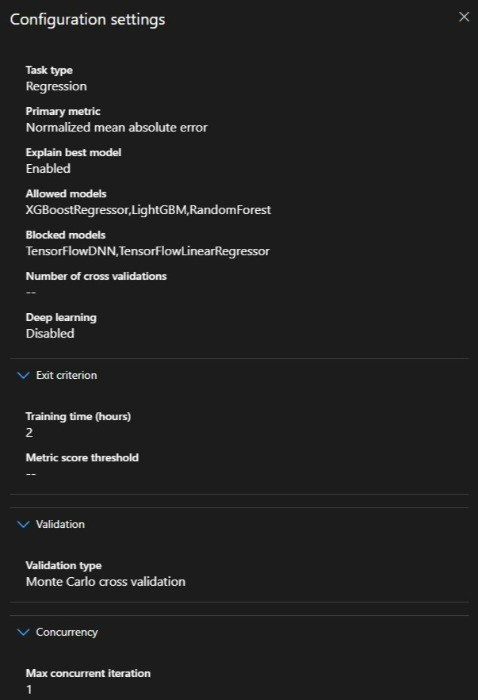
- Building a benchmark model quickly with AutoML
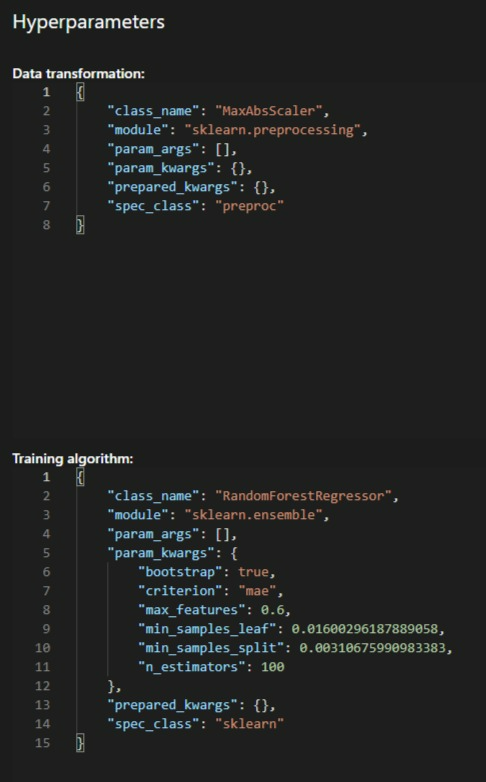
- Designing a custom notebook workflow for deeper control
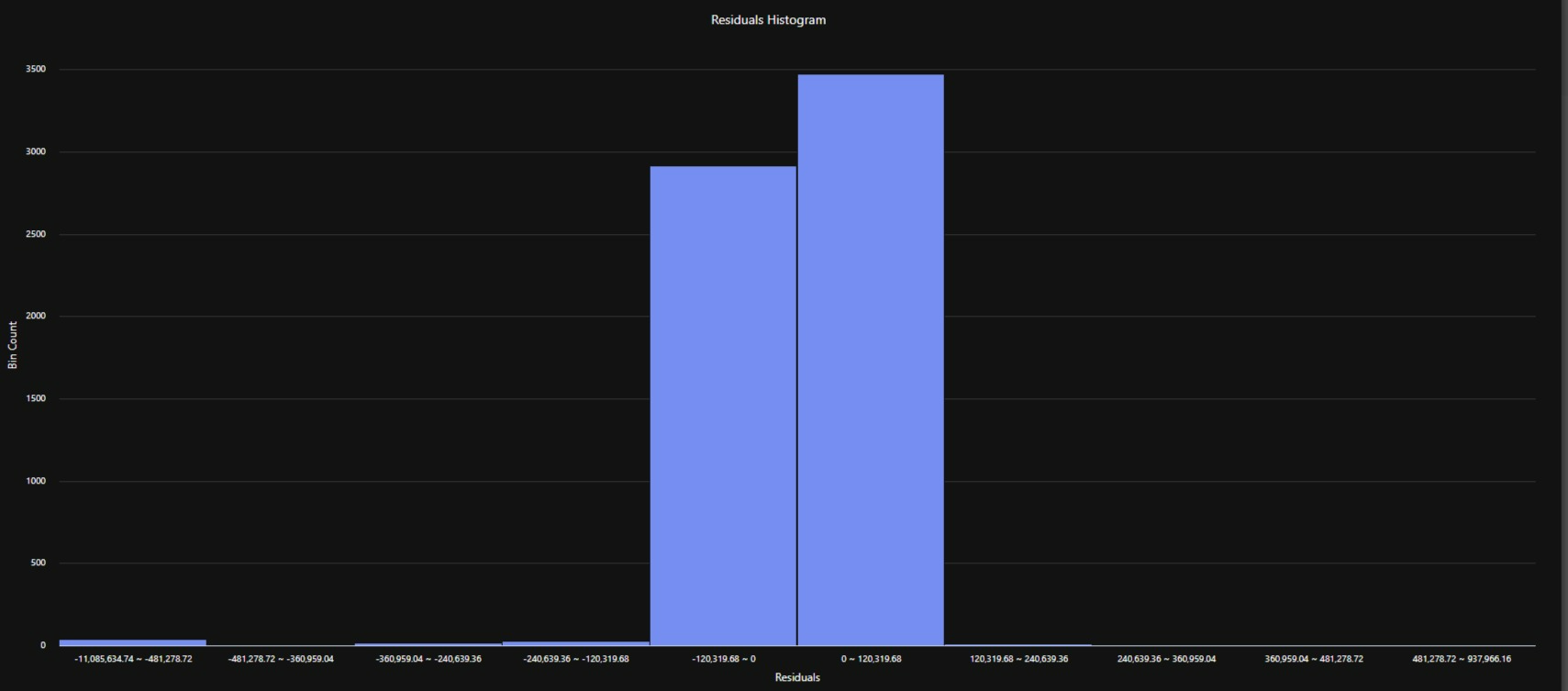
- Comparing speed, transparency, and model quality
- Thinking about model development as an analytics decision, not just a tool choice